Selected work · 2026–present
Goldeneye Research Terminal
A research and paper-trading terminal built to measure decision quality
A good decision and a good outcome are not the same thing — and almost nothing in finance is built to tell them apart.
Over short horizons, market outcomes are dominated by noise. A well-reasoned position can lose and a careless one can win, and conventional performance measurement cannot distinguish the two. The decision-analytics tools that do attempt to measure skill work backward from executed trades, reconstructing the quality of a judgment after the fact from the record it left behind. What none of them capture is the thing that actually constitutes the decision: what the analyst believed, and with what confidence, at the moment the belief was formed. Goldeneye begins from that absence.
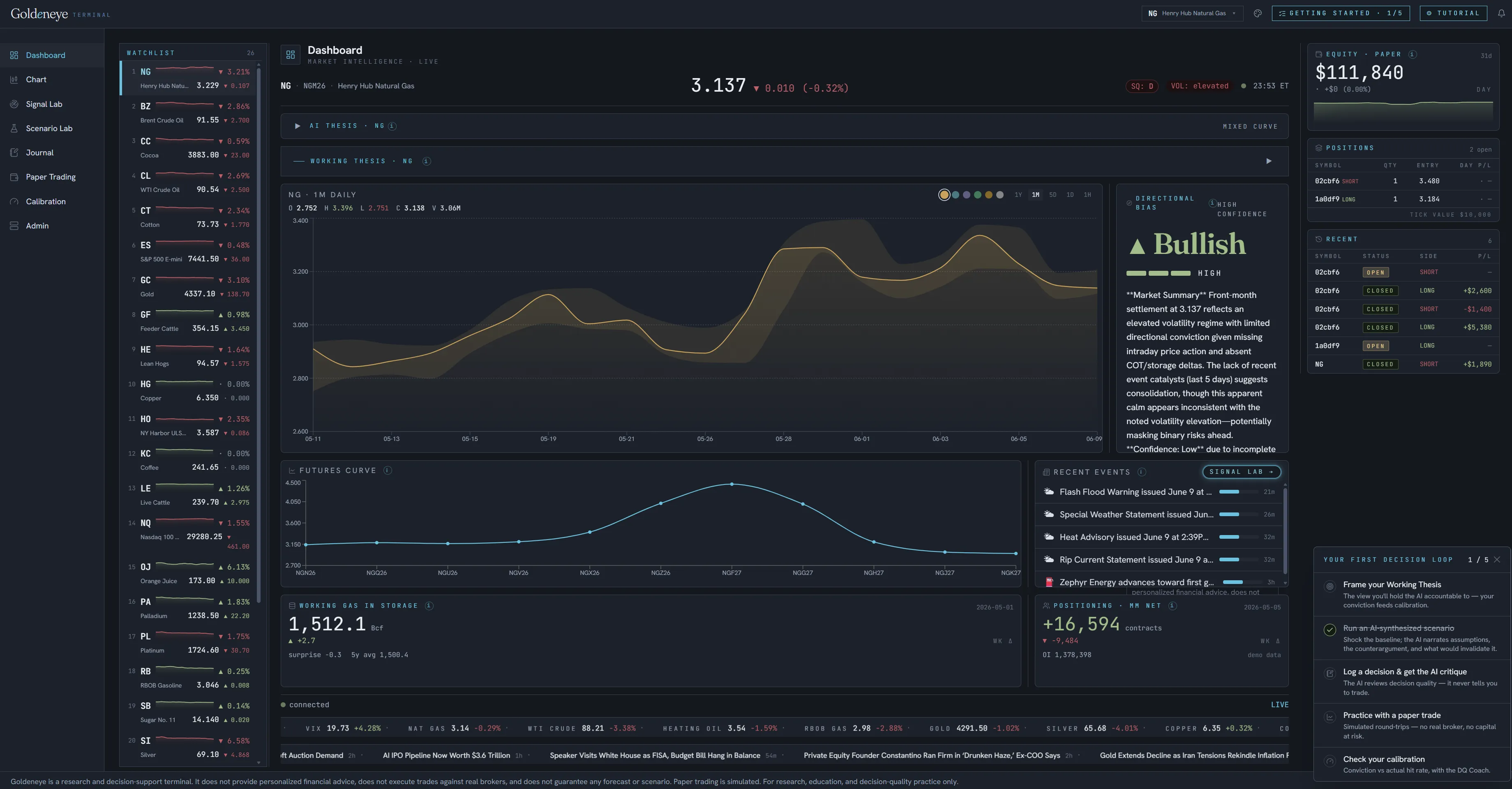
Goldeneye is a research and paper-trading terminal for commodity markets — natural gas first, with crude, refined products, and metals following. It treats the analyst’s working thesis as a first-class object: every entry records the evidence the analyst saw, the counterarguments they weighed, and the conviction they assigned, anchored to a stated probability. When the market resolves, a decision-quality engine scores each entry against realized prices and builds a personal reliability diagram — conviction claimed against hit rate achieved, bucketed with sample-size guardrails. Around that core sit an explainable four-model forecast ensemble (moving-average crossover, volatility regime, Prophet, and a factor composite) backtested under strict look-ahead controls; a scenario lab for applying counterfactual shocks — weather, LNG exports, production, storage — to a baseline forecast; adapters to official public data from the EIA, CFTC, and National Weather Service; and a language-model layer, built on Claude, constrained by a safety architecture that forbids advice and guarantee language and derives its stated confidence from model agreement rather than asserting a fixed value. The system was designed and built solo, using Claude and Claude Code as development tools, and runs in production on Next.js, FastAPI, and TimescaleDB.

The real difficulty was not the forecasting; it was the integrity of the measurement. Three problems recurred. First, proving the absence of look-ahead bias. Most backtests leak future information in small, hard-to-see ways, and a calibration claim built on a leaky backtest is worthless. The unusual move here was to invert the usual practice: rather than trusting the engine not to cheat, the system includes a model designed to cheat, and the test suite fails if that model is not caught. Temporal honesty is demonstrated, not asserted. Second, representing uncertainty in a domain whose culture rewards false confidence. The commercial language of markets is the language of conviction; an instrument whose purpose is to make a user’s overconfidence legible — and which is structurally unable to flatter that user — runs against the grain of the field it serves. Third, not letting the demonstration outrun the evidence. During development, results that looked too clean turned out to rest on fabricated or force-fed outcomes, and were discarded. What the instrument reports is scored by the resolution engine against real delayed prices; illustrative material is labeled as illustrative rather than presented as a track record.
The research claim is that decision quality is measurable independently of outcome, and that the correct place to measure it is ex ante — the conviction held at the moment of decision — rather than the trade reconstructed afterward. The mathematics is not new: Brier scoring and reliability diagrams come out of weather forecasting and run through Tetlock’s work on judgment and platforms such as Metaculus. The contribution is the application — bringing that calibration apparatus to discretionary financial research at the point of decision, with provable temporal integrity, inside a single loop from thesis to outcome. Underneath the financial framing is a humanistic one. An instrument that cannot overstate certainty is a claim about how people reason: that making one’s own calibration visible is an intervention, not merely a report. This is the idea, familiar from the study of games, of resulting — judging a decision by how it turned out rather than by how it was made — rebuilt as a working instrument that refuses to do so.
It is worth being plain about what the project does not claim. It has no demonstrated out-of-sample directional edge; the forecasting components earn their place as honest infrastructure, not as a source of alpha. The claim is about the measurement of judgment, not the prediction of prices.